Introduction
The dawn of autonomous vehicles is upon us, transforming the futuristic concept of self-driving cars into a tangible reality on our streets. Predictions from as early as 2015 suggested that by 2020, front seat drivers would transition to backseat passengers, fueled by ambitious declarations from industry giants like General Motors, Google, and Tesla. While these tech pioneers have invested immense resources to perfect autonomous functionality, widespread adoption beyond trial programs, such as Tesla’s Autopilot for highway driving, remains pending. Alongside technical hurdles and infrastructure readiness, ethical considerations surrounding self-driving cars significantly contribute to this delay. One crucial, often overlooked aspect underpinning these ethical dilemmas is the sheer scale and complexity of the programming that governs these vehicles. But just how extensive is the software powering a self-driving car? How many bytes is a self-driving car’s programming? Understanding the magnitude of this code is essential to grasping the challenges and ethical implications inherent in autonomous technology.
The ethical debate surrounding self-driving cars is multifaceted, influenced by subjective viewpoints shaped by cultural backgrounds, personal values, and philosophical stances. A central point of contention arises in accident scenarios, sparking two primary ethical concerns. The first is a post-accident analysis focused on accountability – determining who or what entity bears responsibility for a crash, be it manufacturers, developers, data providers, owners, or other road users. The second, and perhaps more complex, concern is a pre-emptive examination of the decision-making processes embedded within self-driving cars. This delves into how these vehicles are programmed to react in unavoidable accident situations. For instance, should a car prioritize hitting an oncoming vehicle or swerving to potentially strike a pedestrian? This conundrum echoes the classic trolley problem, highlighting the intricate ethical choices programmed into autonomous systems.
The Software Backbone of Self-Driving Cars
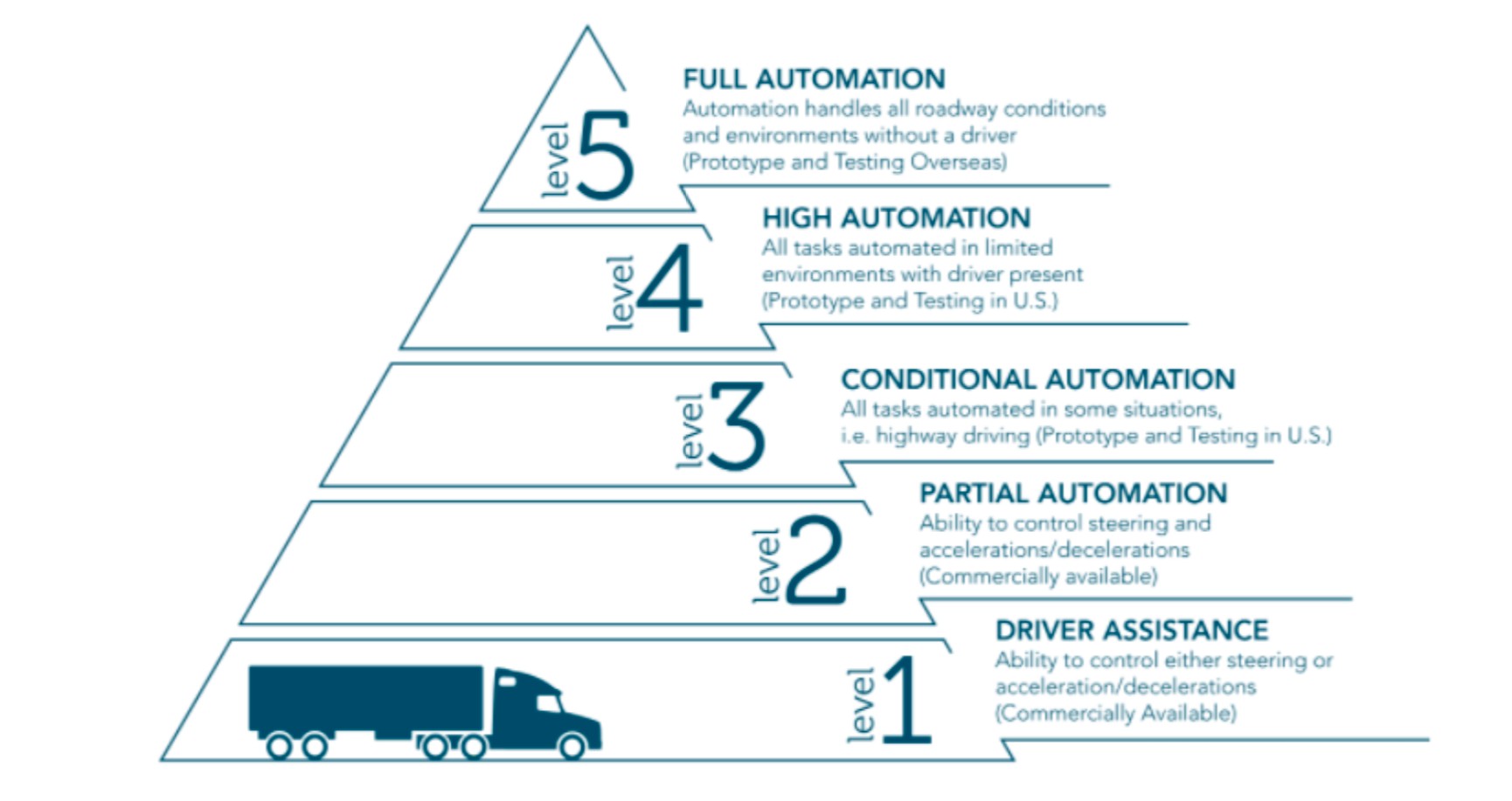
The pursuit of vehicle automation is driven by the promise of enhanced safety, reduced pollution, and improved energy efficiency. The core objective is to create cars that operate with heightened reliability and efficiency through standardized systems, minimizing or eliminating human intervention. The degree of this “automation” in car manufacturing is categorized into levels defined by the US National Highway Traffic Safety Administration (NHTSA), as illustrated in Figure No.1.
Figure No.1: Autonomous Driving Levels
From Level 1, where driver responsibility is paramount, to higher levels with increasing automation, the question of accountability in accidents becomes progressively intricate. The ethical dilemma concerning decision-making algorithms takes center stage from Level 3 upwards. Here, automation begins to act as a decision-maker – limited in Level 3 but fully autonomous in Level 5 – taking over roles traditionally performed by human drivers. This transition underscores the critical importance of the underlying software and, by extension, the sheer volume of programming required to navigate the complexities of real-world driving scenarios. The question of “how many bytes” becomes more than just a technical query; it reflects the immense scope of instructions needed to imbue a machine with ethical decision-making capabilities.
The Trolley Problem in the Code
The ethical quandaries presented by self-driving cars are frequently framed through the lens of the trolley problem, a moral paradox first introduced by Philippa Foot in 1967. This thought experiment poses a scenario where a runaway trolley is barreling towards five individuals tied to the tracks. A bystander has the option to pull a lever, diverting the trolley to a different track where only one person is tied. The dilemma forces a choice between inaction, resulting in five deaths, or active intervention, causing the death of one to save five.
In the context of self-driving cars, the vehicle itself embodies the trolley, and the “lever panels” are predetermined by manufacturers, specifically programmers, who act as preemptive bystanders. They must anticipate and code for a multitude of hypothetical accident scenarios. Unlike the trolley problem’s potential for passive inaction, self-driving car programming necessitates a programmed response for every eventuality. Every outcome becomes a pre-set “lever pull.” Should the car maintain its lane, risking passenger injury, or swerve to avoid passengers, potentially endangering pedestrians? Do factors like the number, age, gender, or perceived social status of pedestrians or passengers influence the programmed decision? Dismissing the need for such “accident-algorithms” is akin to assuming invincibility, a dangerous fallacy. Therefore, the programming of self-driving cars must encompass decision rules for a range of hypothetical, often ethically fraught, scenarios. As Bonnefon and Rahwan argue, algorithms need to be trained with moral principles to guide decision-making when harm is unavoidable. This necessitates vast amounts of code, data, and sophisticated algorithms, pushing the byte count of self-driving car programming into significant territories.
MIT’s Moral Machine: Quantifying Ethical Preferences in Gigabytes?
Developing universally accepted moral principles for self-driving cars is a formidable challenge, as ethical judgments are inherently subjective and context-dependent. To navigate this complexity, researchers are exploring data-driven approaches to understand and quantify societal preferences in autonomous vehicle ethics. MIT Media Lab’s Moral Machine experiment exemplifies this effort. This online platform simulates various trolley problem scenarios and crowdsources user decisions on how self-driving cars should behave in each situation.
Figure No.2: A hypothetical scenario from the Moral Machine website
Moral Machine gathers large-scale data on individual preferences regarding moral dilemmas in unavoidable accident scenarios. Users are presented with two possible outcomes – the self-driving car swerving or staying its course – and asked to choose. The scenarios vary based on characteristics of the individuals involved, such as gender, age, social status, occupation, physical appearance, and whether they are pedestrians or passengers, and if pedestrians are crossing legally or jaywalking.
This experiment provides valuable empirical insights into globally preferred moral judgments by identifying patterns in responses to hypothetical dilemmas. The platform records choices alongside respondents’ demographic information, including country of residence, age, gender, income, and political and religious views. The vast dataset collected by Moral Machine has the potential to inform the development of ethical principles for self-driving cars, reflecting socially acceptable preferences. For instance, the data reveals strong global preferences for saving humans over animals, saving more lives over fewer, and prioritizing younger lives over older ones. These preferences can serve as foundational elements for programming self-driving car behavior or at least provide crucial input for policymakers. However, Rahwan, a researcher associated with Moral Machine, emphasizes the importance of diverse and even conflicting opinions, recognizing the absence of a universal ethical code for robotics. While initiatives like the German Ethics Commission on Automated and Connected Driving offer guidelines, they also highlight the complexities and contradictions in applying generalized ethical principles. For example, while agreeing on prioritizing human life and minimizing harm, the German guidelines prohibit discrimination based on personal characteristics like age or gender, directly contrasting with preferences observed in the Moral Machine data. This highlights the challenge of translating broad ethical principles into concrete, byte-level instructions for autonomous vehicles, further emphasizing the complexity of self-driving car programming and the sheer volume of code required to handle these nuanced ethical considerations.
Critiques of the Trolley Problem Analogy: Beyond Binary Choices in Code
While the trolley problem and platforms like Moral Machine effectively initiate discussions on ethical dilemmas in self-driving cars, their analogy has limitations in fully capturing the complexities of real-world autonomous vehicle ethics. The analogy has faced criticism for several reasons.
Firstly, while these thought experiments deepen ethical discussions, they don’t provide a universally accepted ethical consensus for programming accident-algorithms. Professor Lin argues that the trolley problem primarily highlights the inherent conflicts between different ethical theories rather than offering definitive solutions. Utilitarianism, for example, would justify diverting the trolley (prioritizing one death over five) based on maximizing overall happiness and minimizing suffering. Conversely, deontology, rooted in Kantian principles, might oppose pulling the lever, adhering to absolute moral principles regardless of outcome. Gogoll and Muller point out that imposing either of these theories could contradict liberal societal values by forcing individuals to act in ways they might not freely choose. Thus, the trolley problem, while illuminating ethical controversies, fails to provide a singular, universally applicable framework for governing self-driving car ethics. This lack of clear ethical direction further complicates the programming process, adding layers of complexity to the already massive codebase.
Secondly, the trolley problem focuses solely on a detached, third-party perspective, neglecting the viewpoints of those directly involved in an accident, such as drivers or passengers. Moral Machine respondents, acting as impartial observers, might make different choices if they themselves were in a simulated accident scenario. This raises concerns about potential bias in data collected from such platforms, questioning whether these preferences truly reflect real-world decision-making under duress.
Thirdly, the trolley problem presents an overly simplified, deterministic scenario that doesn’t reflect the probabilistic nature of real-life traffic accidents. It offers clear-cut, fatal outcomes for each choice, whereas real-world accidents involve probabilities and risk assessments. Self-driving car programming must deal with probabilistic outcomes – coding for scenarios where action A makes hitting a pedestrian X percent less likely than action B. The trolley problem’s simplification of choice and its focus on certain death fail to capture the nuances of risk assessment and probabilistic decision-making inherent in autonomous driving. The byte count of self-driving car programming isn’t just about implementing simple “if-then-else” scenarios like the trolley problem; it’s about creating complex algorithms that can process vast amounts of sensor data, predict probabilities, and make split-second decisions in uncertain, dynamic environments.
Policy Considerations and the Future of Autonomous Code Governance
- Ethical Settings Tool: Customization vs. Standardization in Autonomous Morality
The trolley problem, while useful for initiating ethical discourse, falls short of providing concrete solutions for programming accident-algorithms due to the lack of universal ethical consensus. Manufacturers cannot unilaterally adopt a single ethical theory to guide their programming. An alternative proposal suggests equipping self-driving cars with an “ethical settings tool,” allowing owners to customize the vehicle’s ethical framework based on their preferences. This approach aims to provide user choice and potentially simplify accountability. However, Professor Lin raises strong objections, highlighting the risk of misuse by individuals with discriminatory or unethical viewpoints. Balancing user customization with the need for standardized ethical frameworks remains a critical policy challenge. How many bytes would be added to the programming to accommodate customizable ethical settings? And how would these settings be regulated and audited to prevent misuse?
- Geographical Implementation of Choice: Regional Ethics in a Globalized World?
Given the difficulty of achieving universal ethical consensus, implementing ethical settings based on narrower boundaries, such as demographic preferences, has been suggested. Moral Machine data reveals geographical variations in ethical preferences, with Latin American respondents, for example, showing a stronger preference for saving younger generations compared to Eastern respondents. This raises the possibility of programming accident-algorithms according to regional ethical expectations. However, this approach introduces complex questions. Which ethical settings should a Latin American-licensed self-driving car adopt while traveling in Eastern territories? How would geographically varying accident-algorithms affect legal liability in cross-border accidents? Would it create legal uncertainty and ethical inconsistencies? While geographical segmentation might offer a pragmatic approach, policymakers must carefully consider the potential for ethical and legal fragmentation.
- Privacy Considerations: Beyond Accident Algorithms in the Byte Budget
Overemphasis on accident-algorithms can overshadow other critical ethical concerns, particularly privacy. Self-driving car technology relies on vast data collection, tracking destinations, routes, and road conditions using sophisticated sensors and GPS navigation. This data collection raises significant privacy concerns, as owners may be unaware of how their personal information is being used and stored. Furthermore, personalized features, such as ethical setting tools, increase privacy vulnerabilities. Aggregated data from self-driving cars also holds significant commercial value, potentially monetized through targeted marketing and personalized insurance premiums. The vehicle data monetization market is already substantial and projected to grow exponentially. Policymakers must address these broader ethical concerns beyond accident-algorithms, focusing on data protection, cybersecurity, and responsible data governance in the age of autonomous vehicles. The “byte budget” of self-driving car programming must not only account for ethical decision-making algorithms but also for robust privacy safeguards and data security measures.
Conclusion: Navigating the Byte-Sized Ethics of Autonomous Driving
The advent of self-driving cars challenges Asimov’s foundational rules of robotics, forcing us to consider programming machines to make ethical decisions in unavoidable harm scenarios. Before widespread deployment, a global dialogue is crucial to establish ethical frameworks and involve policymakers in regulation. The trolley problem serves as a valuable starting point for this conversation, prompting essential questions, though it doesn’t provide definitive answers. It highlights the complexities and trade-offs inherent in programming autonomous morality. Ultimately, understanding “how many bytes is a self-driving car’s programming” is not just a technical exercise. It’s about recognizing the vast scale of code required to embody complex ethical decision-making, navigate real-world uncertainties, and ensure responsible and safe autonomous mobility. The future of self-driving cars hinges not only on technological advancements but also on our ability to ethically program these machines, ensuring their byte-level instructions align with human values and societal well-being.